[21-01-2022] Come può il web scraping supportare l'acquisizione separata di singoli contenuti dai siti web?
Quando si archivia un sito web [1], può essere giustificato dal punto di vista dell'archivio registrare individualmente alcuni contenuti e renderli accessibili agli utenti. Nel caso di contenuti analogici, l'impegno del personale aumenta notevolmente con la profondità dell'acquisizione e dell'indicizzazione. Con i contenuti digitali come i siti web, questo può essere potenzialmente evitato grazie a processi di acquisizione digitale automatizzati.
Webscraping
Il web scraping descrive il processo di estrazione di dati e contenuti dai siti web in modo automatizzato. Il web harvesting è spesso usato come sinonimo di web scraping. Il webscraping ha acquisito grande importanza con l'avvento dei Big Data nell'e-commerce e nell'e-advertising, che si riflette in un'ampia gamma di strumenti disponibili. Tuttavia, è stato utilizzato solo sporadicamente in biblioteche e archivi, ad esempio nel progetto europeo BlogForever [2], completato nel 2013, o nel progetto Web Scraping Toolkit della Brown University Library [3].
Strumenti di scraping del web
Per i web scrapers, da un lato, esistono strumenti per i casi d'uso più comuni nel campo dell'e-commerce. D'altra parte, i web scrapers possono anche essere creati con kit di strumenti in base alle esigenze. Di seguito vengono presentate alcune soluzioni note.
Strumenti
Gli strumenti hanno un'interfaccia utente visiva con possibilità di interazione predefinite. Il contenuto da sottoporre a scraping può di solito essere compilato liberamente. Ad esempio, il titolo e il contenuto di un articolo possono essere selezionati separatamente e poi estratti come elemento descrittivo e di contenuto di un pacchetto di dati.
Frameworks, librerie di programmi, Toolkits
Lo scraper viene creato dall'utente con un toolkit o simili.
I kit di strumenti sono open source/non commerciali. Ampiamente utilizzati sono, tra gli altri, i seguenti:
Web Scraper: semplice e versatile
A causa dei vantaggi di Web Scraper menzionati in precedenza, di seguito viene illustrato come viene implementato lo scraping del Web con il componente aggiuntivo Web Scraper e quali sono i vantaggi di Web Scraper.

Struttura ad albero del Web Scraper
Partendo da una pagina iniziale (radice), l'utente può arrivare a livelli più profondi di un sito Web selezionando i collegamenti. In questo modo
È possibile selezionare gruppi di collegamenti e collegamenti paginati. Se l'utente continua a lavorare con un link del gruppo, le regole di scraping si applicano anche a tutti gli altri link del gruppo. Alla fine della struttura ad albero si trova il contenuto da raschiare.
La struttura ad albero può essere visualizzata in Web Scraper. L'albero è memorizzato in json. Il file json può essere modificato manualmente e riutilizzato.
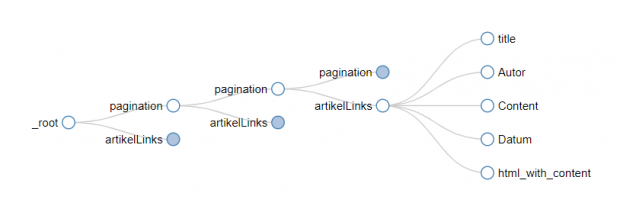
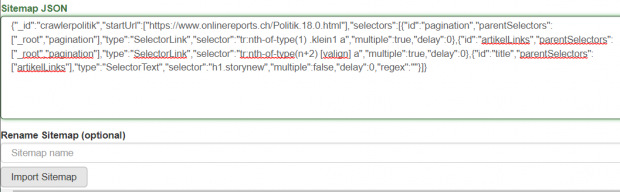
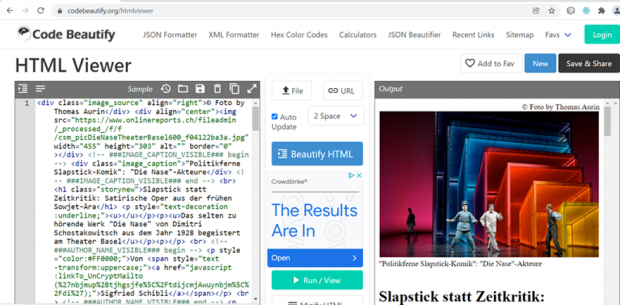
Il contenuto da scrapare è costituito da elementi HTML. Questi vengono selezionati singolarmente e nel loro insieme danno luogo a un elemento di dati. In questo modo, i metadati (ad esempio, autore, titolo) e i contenuti associati (ad esempio, articoli) possono essere scrapati separatamente. Anche l'intera struttura HTML può essere estratta come contenuto. In questo modo, è possibile archiviare anche la rappresentazione, ad esempio, di articoli su un sito web.

Lo scraping viene effettuato tramite il menu della mappa del sito. Dopo lo scraping, è disponibile un file XLS. Ogni dato occupa una riga.
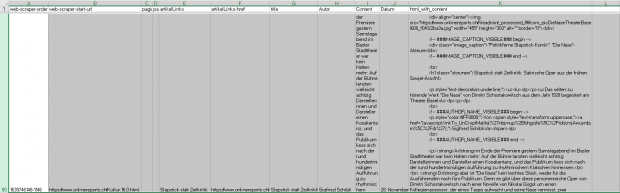
Con strumenti adeguati, gli elementi dei dati nell'XLS possono essere archiviati individualmente e resi accessibili agli utenti tramite un visualizzatore HTML.
Un'attenzione particolare nell'uso archivistico dei contenuti scraped merita i link morti che si verificheranno nel tempo[13]. Se un contenuto scraped non può più accedere e visualizzare un'immagine a causa di un link morto, e questa immagine è necessaria per comprendere il contenuto, ciò è problematico dal punto di vista archivistico. Il modo in cui questo problema può essere risolto è ancora aperto.
Esempio di link a un'immagine morta:
https://www.nzz.ch/bilder/dossiers/2001/afghanistan/afghanistan_indexbild.gif
Conclusione
Attualmente il web scraping è poco utilizzato negli archivi, quindi le esperienze corrispondenti sono rare. I test di CECO con i web scraper Portia, ParseHub e Web Scraper hanno dimostrato che solo Web Scraper è convincente sia in termini di facilità d'uso che di ampiezza delle funzionalità.
Se in futuro dovesse risultare che uno strumento come Web Scraper non è più sufficiente per l'archiviazione del web, si dovrebbe prevedere un progetto che colmi le lacune individuate. In questo caso, è possibile utilizzare la base di conoscenze creata dal progetto "Web Scraping Toolkit"[14].