[21-01-2022] Wie kann Webscraping die separate Übernahme einzelner Inhalte von Websites unterstützen?
Bei der Archivierung einer Website [1] kann es aus Sicht des Archives gerechtfertigt sein, gewisse Inhalte einzeln zu erfassen und den Nutzern zugänglich zu machen. Bei analogen Inhalten steigt der personelle Aufwand mit der Erfassungs- und Erschliessungstiefe stark an. Bei digitalen Inhalten wie Websites kann dies dank automatisierter, digitaler Erfassungsprozesse potenziell vermieden werden.
Webscraping
Webscraping beschreibt den Prozess, in automatisierter Weise Daten und Inhalte von Websites zu extrahieren. Webharvesting wird oft als Synonym für Webscraping verwendet. Webscraping gewann mit dem Aufkommen von Big Data in E-Commerce und E-Advertising grosse Bedeutung, was sich in einer breiten Palette verfügbarer Tools widerspiegelt. In Bibliotheken und Archiven wurde es jedoch bislang nur vereinzelt angewendet, zum Beispiel im 2013 abgeschlossenen EU-Projekt BlogForever [2] oder im Projekt Web Scraping Toolkit der Bibliothek der Brown University[3].
Webscraping-Tools
Für Webscraper gibt es einerseits Tools für häufige Anwendungsfälle aus dem Bereich E-Commerce. Andererseits können Webscraper bedürfnisgerecht auch mit Toolkits erstellt werden. Nachfolgend werden einige bekannte Lösungen vorgestellt.
Tools
Tools verfügen über eine visuelle UI mit vordefinierten Interaktionsmöglichkeiten. Zu scrapende Inhalte können meist frei zusammengestellt werden. So können z.B. Titel und Inhalt eines Artikels separat selektiert und anschliessend als beschreibendes und als inhaltliches Element eines Datenpaketes extrahiert werden.
Frameworks, Programmbibliotheken, Toolkits
Der Scraper wird durch den Anwender mit einem Toolkit o.ä. erstellt.
Die Toolkits sind open source/nicht kommerziell. Verbreitet sind unter anderem:
Web Scraper: einfach und vielfältig
Aufgrund der erwähnten Vorteile von Web Scraper wird in der Folge illustriert, wie ein Webscraping auf dem Web Scraper-Add-On umgesetzt wird und welche Vorteile der Web Scraper aufweist.

Strukturbaum des Web Scraper
Ausgehend von einer Startseite (root) kann sich der Benutzer im Web Scraper durch das Anwählen von Links in tiefere Ebenen einer Website vorarbeiten. Hierbei können
auch ganze Gruppen von Links angewählt werden wie auch paginierte Links. Wird mit einem Link der Gruppe weitergearbeitet, so gelten dessen Scraping-Regeln auch für alle anderen Links der Gruppe. Am Ende des Strukturbaumes steht der zu scrapende Inhalt.
Der Strukturbaum kann in Web Scraper visualisiert werden. Der Baum ist in json hinterlegt. Das json-File kann manuell abgeändert werden und wiederverwendet werden.
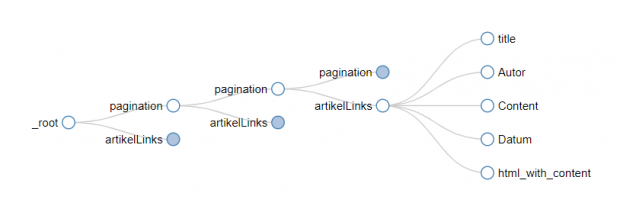
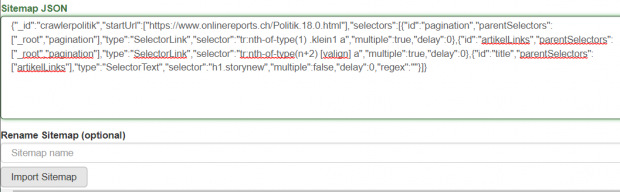
Der zu scrapende Content besteht aus HTML-Elementen. Diese werden einzeln angewählt und ergeben in ihrer Gesamtheit ein Datenelement. So können separat Metadaten (z.B. Autor, Titel) als auch zugehörige Inhalte (z.B. Artikel) gescraped werden. Als Inhalt ist auch die gesamte HTML-Struktur extrahierbar. Somit lässt sich die Repräsentation z.B. von Artikeln auf einer Webseite ebenfalls archivieren.

Über das Sitemapmenu wird das scraping ausgeführt. Nach dem scraping steht ein XLS-File zur Verfügung. Jedes Datenelement nimmt hierbei eine Zeile ein.
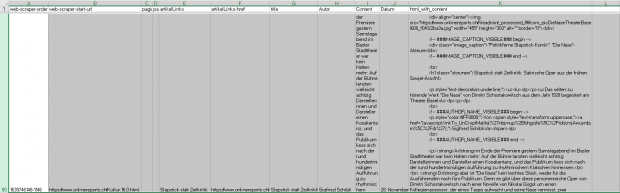
Mit geeigneten Tools lassen sich die Datenelemente im XLS einzeln archivieren und den Benutzern über einen HTML-Viewer zugänglich machen.
Ein besonderes Augenmerk bei der archivischen Verwendung von gescrapten Inhalten verdienen tote Links, die mit der Zeit auftreten werden[13]. Wenn ein gescrapter Inhalt aufgrund eines toten Links ein Bild nicht mehr aufrufen und darstellen kann, und dieses Bild für das Verständnis des Inhaltes notwendig ist, so ist dies aus archivischer Sicht problematisch. Wie dieses Problem gelöst werden kann, ist noch offen.
Beispiel eines toten Bildlinks:
https://www.nzz.ch/bilder/dossiers/2001/afghanistan/afghanistan_indexbild.gif
Fazit
Aktuell wird Webscraping in Archiven kaum verwendet, entsprechende Erfahrungen sind deshalb rar. Die Tests der KOST mit den Webscrapern Portia, ParseHub und Web Scraper zeigten auf, dass nur Web Scraper sowohl bezüglich Bedienfreundlichkeit als auch Funktionalitätsbreite zu überzeugen vermag.
Falls sich künftig herausstellen sollte, dass für archivisches Webscraping ein Tool wie Web Scraper nicht mehr genügt, so ist ein Projekt ins Auge zu fassen, welches die erkannten Lücken füllt. Hierbei kann auf die vom «Web Scraping Toolkit»[14] -Projekt geschaffene Wissensbasis zurückgegriffen werden.