[21-01-2022] Comment le Webscraping peut-il soutenir la reprise séparée de contenus individuels de sites web?
Le site a été traduit de l'allemand vers le français à l'aide du logiciel Deepl.
Lors de l'archivage d'un site web [1] il peut être justifié du point de vue des archives de saisir individuellement certains contenus et de les rendre accessibles aux utilisateurs. Pour les contenus analogiques, l'investissement en personnel augmente fortement avec la profondeur de la saisie et de l'indexation. Pour les contenus numériques tels que les sites web, cela peut potentiellement être évité grâce à des processus de saisie numériques automatisés.
Webscraping
Le webcraping décrit le processus d'extraction automatisée de données et de contenus de sites web. Le webharvesting est souvent utilisé comme synonyme de webcraping. Le webcraping a pris une grande importance avec l'avènement du big data dans le commerce électronique et la publicité en ligne, ce qui se reflète dans la large palette d'outils disponibles. Dans les bibliothèques et les archives, il n'a toutefois été utilisé jusqu'à présent que de manière isolée, par exemple dans le projet européen BlogForever, achevé en 2013. [2] ou dans le project Web Scraping Toolkit de la bibliothèque de Brown University[3].
Webscraping-Outils
Pour les webscrapers, il existe d'une part des outils pour les cas d'application fréquents dans le domaine du commerce électronique. D'autre part, les webscrapers peuvent être créés en fonction des besoins à l'aide de kits d'outils. Quelques solutions connues sont présentées ci-dessous.
Outils
Les outils disposent d'une interface visuelle avec des possibilités d'interaction prédéfinies. Les contenus à analyser peuvent généralement être assemblés librement. Par exemple, le titre et le contenu d'un article peuvent être sélectionnés séparément et ensuite extraits en tant qu'éléments descriptifs et de contenu d'un paquet de données.
Frameworks, bibliothèques de programmes, toolkitsLe scraper est créé par l'utilisateur à l'aide d'un toolkit ou similaire. Les kits d'outils sont open source/non commerciaux. Les plus répandus sont entre autres
Web Scraper: simple et polyvalent
En raison des avantages mentionnés de Web Scraper, nous illustrons ci-après comment un web scraping est mis en œuvre sur le Web Scraper-Add-On et quels sont les avantages de Web Scraper.

Arborescence du Web Scraper
En partant d'une page d'accueil (root), l'utilisateur peut se rendre dans les niveaux inférieurs d'un site web en sélectionnant des liens dans le Web Scraper. Il est possible de sélectionner
des groupes entiers de liens peuvent être sélectionnés, ainsi que des liens paginés. Si le travail se poursuit avec un lien du groupe, ses règles de scraping s'appliquent également à tous les autres liens du groupe. Le contenu à scraper se trouve à la fin de l'arborescence.
L'arborescence peut être visualisée dans Web Scraper. L'arborescence est stockée en json. Le fichier json peut être modifié manuellement et réutilisé.
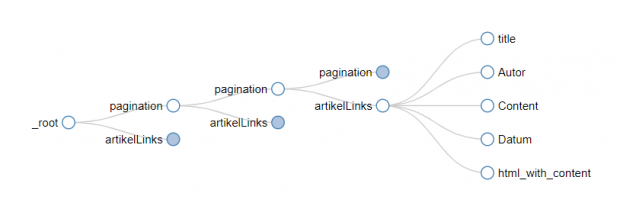
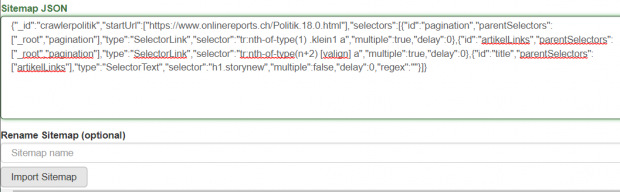
Le contenu à scrapper se compose d'éléments HTML. Ceux-ci sont sélectionnés individuellement et forment dans leur ensemble un élément de données. Ainsi, il est possible de scraper séparément les métadonnées (par ex. auteur, titre) et les contenus correspondants (par ex. articles). La structure HTML complète peut également être extraite en tant que contenu. Ainsi, la représentation d'articles sur un site web, par exemple, peut également être archivée.
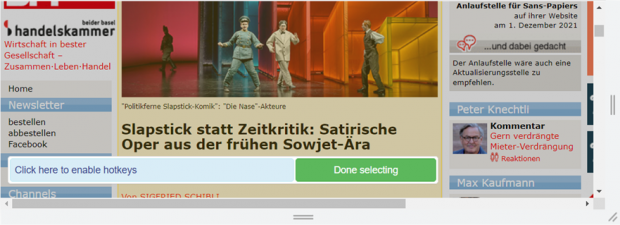

Le scraping est effectué via le menu du plan du site. Après le scraping, un fichier XLS est disponible. Chaque élément de données occupe une ligne.
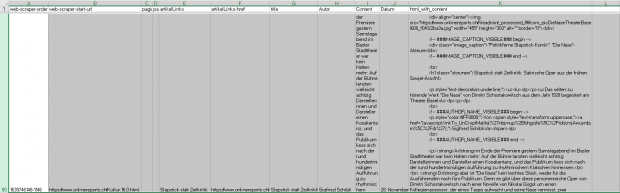
Des outils appropriés permettent d'archiver individuellement les éléments de données dans le XLS et de les rendre accessibles aux utilisateurs via une visionneuse HTML.
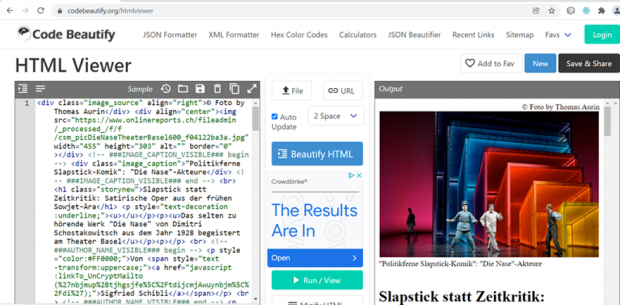
Une attention particulière doit être accordée à l'utilisation archivistique des contenus scrapés, car les liens morts apparaissent avec le temps.[13]. Si un contenu scrapé ne peut plus appeler et représenter une image en raison d'un lien mort, et que cette image est nécessaire à la compréhension du contenu, cela pose problème du point de vue archivistique. La manière dont ce problème peut être résolu n'est pas encore déterminée.
Exemple de lien d'image morte:
https://www.nzz.ch/bilder/dossiers/2001/afghanistan/afghanistan_indexbild.gif
Conclusion
Actuellement, le web scraping n'est guère utilisé dans les archives, les expériences correspondantes sont donc rares. Les tests effectués par le CECO avec les Webscrapers Portia, ParseHub et Web Scraper ont montré que seul Web Scraper est convaincant, tant en termes de convivialité que de fonctionnalités.
S'il devait s'avérer à l'avenir qu'un outil tel que Web Scraper ne suffit plus pour le web scraping archivistique, il faudrait envisager un projet qui comblerait les lacunes constatées. Pour ce faire, il est possible de recourir à la base de connaissances créée par le projet "Web Scraping Toolkit"[14]